
Graphcore IPU-M2000 übertrifft GPUs in ersten Benchmarks deutlich
Branchenweit führende KI-Computing-Lösungen ab sofort weltweit verfügbar.

Graphcore hat die ersten Performance-Benchmarks für seine neuesten KI-Computing-Lösungen, die Intelligence Processing Unit IPU-M2000 und die Scale-Out-Lösung IPU-POD64, veröffentlicht.
Bei gängigen Modellen haben die Graphcore-Lösungen den A100 von NVIDIA (DGX-basiert) deutlich übertroffen – sowohl beim KI-Training als auch bei der Inferenz.
Zu den Benchmark-Highlights zählen:
Training:
- EfficientNet-B4: 18-mal höherer Durchsatz
- ResNeXt 101: 3,7-mal höherer Durchsatz
- BERT-Large: 5,3-mal schnelleres Training des IPU-POD64 im Vergleich zum DGX A100 (>2,6-mal schneller als Dual-DGX-Systeme)
Inferenz:
- LSTM: >600-facher Durchsatz bei geringerer Latenz
- EfficientNet-B0: 60-facher Durchsatz / >16-mal geringere Latenz
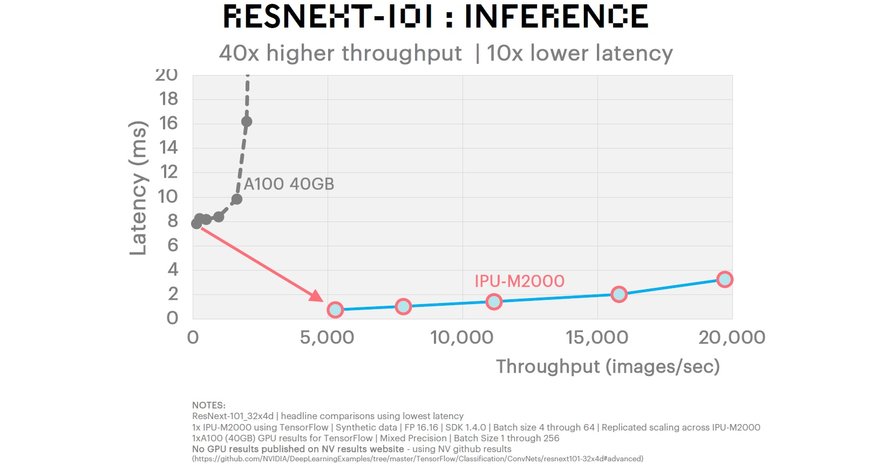
- ResNeXt 101: 40-facher Durchsatz / 10-mal geringere Latenz
- BERT-Large: 3,4-mal höherer Durchsatz bei geringerer Latenz
[Alle Graphcore-Benchmarks sind hier einsehbar.
NVIDIA-Benchmarks basieren auf veröffentlichten Daten.]
In den Benchmarks sind Ergebnisse für BERT-Large enthalten, ein Transformer-basiertes Verarbeitungsmodell für natürliche Sprache, das auf allen 64 Prozessoren des IPU-POD64 ausgeführt wird.
Mit einer Trainingszeit, die 5,3-mal schneller als die des neuesten NVIDIA DGX-A100 ist (>2,6-mal schneller als ein Dual-DGX-Setup), veranschaulicht das BERT-Large-Ergebnis die Leistungsfähigkeit der IPU-POD64 Scale-Out-Lösung von Graphcore für Rechenzentren sowie die Leistungsfähigkeit des Poplar-Software-Stacks zur Verwaltung komplexer Workloads, die die Vorteile mehrerer parallel arbeitender Prozessoren nutzen.
„Diese umfassende Reihe von Benchmarks zeigt, dass die IPU-M2000 und der IPU-POD64 von Graphcore die GPUs bei gängigen Modellen auf ganzer Linie übertreffen“, sagte Matt Fyles, Senior Vice President Software, Graphcore. „Die Benchmarks für neuere Modelle wie EfficientNet sind besonders aufschlussreich, da sie zeigen, wie die Weiterentwicklung der KI die spezielle Architektur der IPU gegenüber dem ‚alten‘ Legacy-Design von GPUs zunehmend bevorzugt. Diese Lücke wird sich weiter vergrößern, wenn Kunden KI-Computing-Lösungen fordern, die mit Sparse-Modeling umgehen und umfangreiche Modelle effizient ausführen können – Aspekte, für die sich die Graphcore IPU besonders auszeichnet.“
MLCommons
Neben der Veröffentlichung umfassender Benchmarks für seine KI-Computing-Lösungen hat Graphcore seine Mitgliedschaft bei MLCommons, dem neu gegründeten Kontrollgremium von MLPerf, bekannt gegeben.
Graphcore wird ab 2021 am vergleichenden Benchmarking-Prozess von MLCommons teilnehmen. Weitere Informationen dazu auch in der Pressemitteilung zum Start von MLCommons.
Ab sofort verfügbar
Die Veröffentlichung der neuen Benchmarks von Graphcore fällt mit der weltweiten Verfügbarkeit der IPU-M2000- und IPU-POD64-Systeme zusammen. Eine Reihe von Systemen ist bereits in Rechenzentren installiert und in Betrieb.
Der Vertrieb wird durch das weltweite Partnernetzwerk von Graphcore sowie durch die eigenen Vertriebs- und Außendienstteams in Europa, Asien und Amerika unterstützt. Zu den Partnern in der DACH-Region zählen u.a. Boston und MEGWARE.
PyTorch und Poplar 1.4
Graphcore-Nutzer können jetzt die Vorteile der Version 1.4 des Poplar SDKs (Software-Entwicklungskits) nutzen, einschließlich vollständigem PyTorch-Support. PyTorch ist zum bevorzugten Framework für Entwickler geworden, die an neuester KI-Forschung arbeiten und gewinnt in der KI-Community zunehmend an Interesse.
Neueste Daten von PapersWithCode belegen, dass 47% der veröffentlichten Arbeiten mit zugehörigem Code das PyTorch-Framework verwenden (September 2020).
Durch die zusätzliche Unterstützung von PyTorch zusammen mit Poplars bereits bestehendem Support für TensorFlow kann die überwiegende Mehrheit der KI-Anwendungen jetzt problemlos auf Graphcore-Systemen zum Einsatz kommen.
Wie bei anderen Elementen des Poplar-Stacks stellt Graphcore seine PyTorch-for-IPU Interface Library als Open-Source-Lösung bereit, damit die Community zu seiner Entwicklung beitragen und diese beschleunigen kann.

Über die IPU-M2000 und IPU-POD64
Die IPU-Machine M2000 ist ein Plug-and-Play KI-Computing-Blade, das für eine einfache Installation konzipiert wurde und Systeme unterstützt, die hoch skalieren. Das schlanke 1HE-Blade liefert 1 PetaFlop KI-Rechenleistung und bietet Netzwerktechnik, die für das KI-Scale-Out optimiert ist.
Jede IPU-Machine M2000 wird von vier der neuen 7nm-Colossus Mk2 GC200-IPU-Prozessoren von Graphcore angetrieben und durch den Poplar-Software-Stack von Graphcore unterstützt.
Die IPU-POD64 ist die Scale-Out-Lösung von Graphcore, die 16 IPU-M2000-Machines umfasst, die mit der IPU-Fabric-Technologie von Graphcore mit extrem hoher Bandbreite vorkonfiguriert und vernetzt sind.
IPU-POD64 wurde für umfangreiche KI-Computing-Funktionen entwickelt, um einzelne Workloads für die parallele Berechnung auf mehrere IPUs zu verteilen oder um sie mithilfe der Virtual-IPU-Software von Graphcore gemeinsam über mehrere Benutzer hinweg zu verwenden.
Über die Colossus Mk2 GC200 IPU
Die Colossus Mk2 GC200 IPU basiert auf neuester 7nm-Prozesstechnologie von TSMC und enthält mehr als 59,4 Mrd. Transistoren auf einem 823mm2-Chip. Mit ihren 1472 separaten IPU-Cores kann die Colossus Mk2 GC200 IPU 8832 separate parallele Computing-Threads ausführen.
Die Leistungsfähigkeit jedes IPU-Cores wird durch eine Reihe neuartiger, von Graphcore entwickelter, Gleitkomma-Techniken namens „AI-Float“ nochmals gesteigert. Durch optimierte arithmetische Implementierungen in Bezug auf Stromverbrauch und Leistungsfähigkeit bei Maschinenintelligenz-Berechnungen steht 1 PetaFlop KI-Rechenleistung mit jedem IPU-Machine M2000 1HE-Blade zur Verfügung.

Mit branchenführendem Support für FP32-IEEE-Gleitkomma-Arithmetik unterstützt Graphcore auch FP16.32 (16Bit-Multiplikation mit 32Bit-Akkumulation) und FP16.16 (16Bit-Multiplikation mit Akkumulation). Die Colossus Mk2 GC200 IPUs unterstützen dabei stochastische Rundung der Arithmetik in Hardware, die mit der vollen Geschwindigkeit des Prozessors ausgeführt wird. Dadurch kann die IPU die gesamte Arithmetik in 16Bit-Formaten halten, was den Speicherbedarf reduziert, Energie bei Lese-/Schreibvorgängen und in der Arithmetik-Logik einspart, während die Ergebnisse der Maschinenintelligenz mit voller Genauigkeit geliefert werden.
Jeder der 1472 Prozessorkerne und 8832 parallelen Programm-Threads kann einen separaten Startwert für einen Zufallszahlengenerator mit Rauschformung erzeugen, was eine einzigartige Rechenleistung ermöglicht, um z.B. Wahrscheinlichkeits- oder Evolutionsstrategie-Modelle zu unterstützen.
Der KI-Fließkomma-Arithmetik-Block unterstützt auch Sparse-Arithmetik-Fließkommaoperationen. Graphcore bietet Bibliotheksunterstützung für verschiedene Sparse-Operationen, einschließlich Block- und Dynamic-Sparsity. Die Colossus Mk2 GC200 IPU bietet nicht nur während der Inferenz, sondern auch während des Trainings eine viel effizientere Berechnung von Sparse-Daten. Dies ermöglicht, neue Arten komplexer Modelle zu erstellen, die mit viel weniger Parametern, kürzeren Trainingszeiten und viel weniger Energie mehr Leistungsfähigkeit auf dem neuesten Stand der Technik bereitstellen können.
www.graphcore.ai
Fordern Sie weitere Informationen an…
